DMI vs. vLLM Hidden State Extraction: 13x More Data with 15-17x Lower Overhead
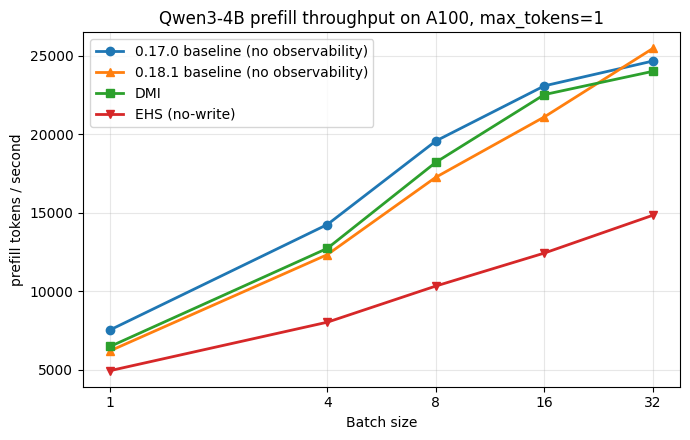
Internal-state extraction is only useful in serving research if it does not dominate the serving workload. We compared DMI with vLLM Hidden State Extraction on Qwen3-4B prefill throughput using a single NVIDIA A100.
The short version: at larger batch sizes, DMI captures about 13x more tensor data per token than vLLM Hidden State Extraction while reducing extraction overhead by about 15-17x.
Prefill Throughput
To compare extraction overhead directly, both runs exclude persistent storage cost and measure prefill throughput while tensors are captured.
| Batch size | DMI overhead | vLLM Hidden State Extraction overhead |
|---|---|---|
| 1 | -14.0% | -20.4% |
| 4 | -10.7% | -34.9% |
| 8 | -6.9% | -40.1% |
| 16 | -2.4% | -41.1% |
| 32 | -2.7% | -41.7% |
At batch size 16, DMI’s prefill overhead is 17.1x lower. At batch size 32, it is 15.4x lower. In throughput terms, DMI reaches 23,995 prefill tokens/sec at batch size 32, while vLLM Hidden State Extraction reaches 14,833 tokens/sec, a 1.62x throughput advantage.
The gap is especially notable because DMI is capturing a much wider tensor surface: residual streams, Q/K/V/Z, MLP tensors, layer-norm tensors, embeddings, logits, and token IDs, compared with hidden states only.
Takeaway
vLLM Hidden State Extraction is a useful hidden-state dumping path. DMI is designed for broader observability with lower overhead in the serving path.
For research that needs a broader internal trace during vLLM inference, the benchmark suggests DMI gives substantially more signal while keeping prefill throughput much closer to the baseline.
Full methodology and raw benchmark context are in the DMI vs. vLLM Hidden State Extraction report.